javaSpringCloud面试题-Eureka / Zookeeper
2024-05-24 13:13:07

Eureka通过⼼跳检测、健康检查和客户端缓存等机制,提⾼系统的灵活性、可伸缩性和可⽤性。

1.us-east-1c、us-east-1d,us-east-1e代表不同的机房,每⼀个Eureka Server都是⼀个集群;
2.Service作为服务提供者向Eureka中注册服务,Eureka接受到注册事件会在集群和分区中进⾏数据同步,Client作为消费端(服务消费者)可以从Eureka中获取到服务注册信息,进⾏服务调⽤;
3.微服务启动后,会周期性地向Eureka发送⼼跳(默认周期为30秒)以续约⾃⼰的信息;
4.Eureka在⼀定时间内(默认90秒)没有接收到某个微服务节点的⼼跳,Eureka将会注销该微服务节点;
5.Eureka Client会缓存Eureka Server中的信息。即使所有的Eureka Server节点都宕掉,服务消费者依然可以使⽤缓存中的信息找到服务提供者;
Eureka缓存
新服务上线后,服务消费者不能立即访问到刚上线的新服务,需要过⼀段时间后才能访问?或是将服务下线后,服务还是会被调⽤到,⼀段时候后才彻底停⽌服务,访问前期会导致频繁报错!
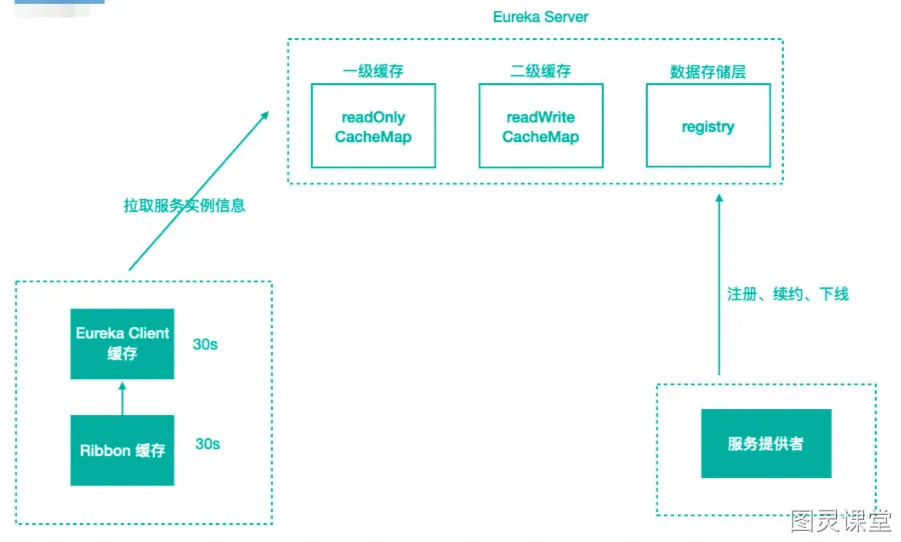

服务注册到注册中⼼后,服务实例信息是存储在Registry表中的,也就是内存中。但Eureka为了提⾼响应速度,在内部做了优化,加⼊了两层的缓存结构,将Client需要的实例信息,直接缓存起来,获取的时候直接从缓存中拿数据然后响应给 Client。
●第⼀层缓存是readOnlyCacheMap,采⽤ConcurrentHashMap来存储数据的,主要负责定时与readWriteCacheMap进⾏数据同步,默认同步时间为 30 秒⼀次。
●第⼆层缓存是readWriteCacheMap,采⽤Guava来实现缓存。缓存过期时间默认为180秒,当服务下线、过期、注册、状态变更等操作都会清除此缓存中的数据。
●如果两级缓存都无法查询,会触发缓存的加载,从存储层拉取数据到缓存中,然后再返回给 Client。Eureka之所以设计⼆级缓存机制,也是为了提⾼ Eureka Server 的响应速度,缺点是缓存会导致 Client获取不到最新的服务实例信息,然后导致⽆法快速发现新的服务和已下线的服务。
解决方案
●我们可以缩短读缓存的更新时间让服务发现变得更加及时,或者直接将只读缓存关闭,同时可以缩短客户端如ribbon服务的定时刷新间隔,多级缓存也导致C层⾯(数据⼀致性)很薄弱。
●Eureka Server 中会有定时任务去检测失效的服务,将服务实例信息从注册表中移除,也可以将这个失效检测的时间缩短,这样服务下线后就能够及时从注册表中清除。
自我保护机制开启条件
●期望最小每分钟能够续租的次数(实例* 频率 * 比例==10* 2 *0.85)
●期望的服务实例数量(10)
健康检查
●Eureka Client 会定时发送心跳给 Eureka Server 来证明自己处于健康的状态;
●集成SBA以后可以把所有健康状态信息一并返回给eureka;
